Transcreva entrevistas sem enviar seu áudio pra nuvem.
Transcritório é um aplicativo de desktop para transcrição automática e separação de falantes em português brasileiro. Roda 100% na sua máquina — sem login, sem assinatura, sem envio de dados.
Windows
Windows 10/11 · 64-bit1.64 GB Clique e execute o instalador macOS
Apple Silicon (M1/M2/M3/M4)608 MB Primeira vez: clique direito > Abrir Linux
x86_64 · AppImage852 MB chmod +x e rode Ainda avaliando? Role a página e veja em 30 segundos por que pesquisadores estão migrando de serviços na nuvem.
- 100% local, sem nuvem
- Separação automática de falantes
- Português brasileiro nativo
- Editor com forma de onda
- Exporta em vários formatos
- Gratuito e código aberto
Como mudam as suas horas de trabalho
Sem Transcritório
- 8 a 10 horas transcrevendo manualmente 1 hora de entrevista.
- Enviar áudio sigiloso para servidores de empresas estrangeiras.
- Mensalidade de R$ 100–300 por serviços de transcrição online.
- Marcar falantes na mão, linha por linha.
- Explicar ao comitê de ética por que o áudio foi para a nuvem.
Com Transcritório
- 15 a 30 minutos de processamento, depois só revisar.
- Áudio nunca sai do seu computador.
- Zero custo, para sempre. Código aberto sob licença MIT.
- Falantes identificados automaticamente e renomeáveis em um clique.
- Texto pronto para colar no projeto de pesquisa (logo abaixo).
Privacidade por desenho, não por promessa
- Processamento 100% local: o áudio da entrevista nunca é enviado a servidores externos.
- Sem coleta de dados, sem telemetria: nenhum cadastro ou login é exigido.
- Código-fonte aberto sob licença MIT: auditável por qualquer pessoa.
- Compatível com LGPD e TCLE: você mantém controle integral sobre o áudio do informante.
Tudo que um pesquisador precisa

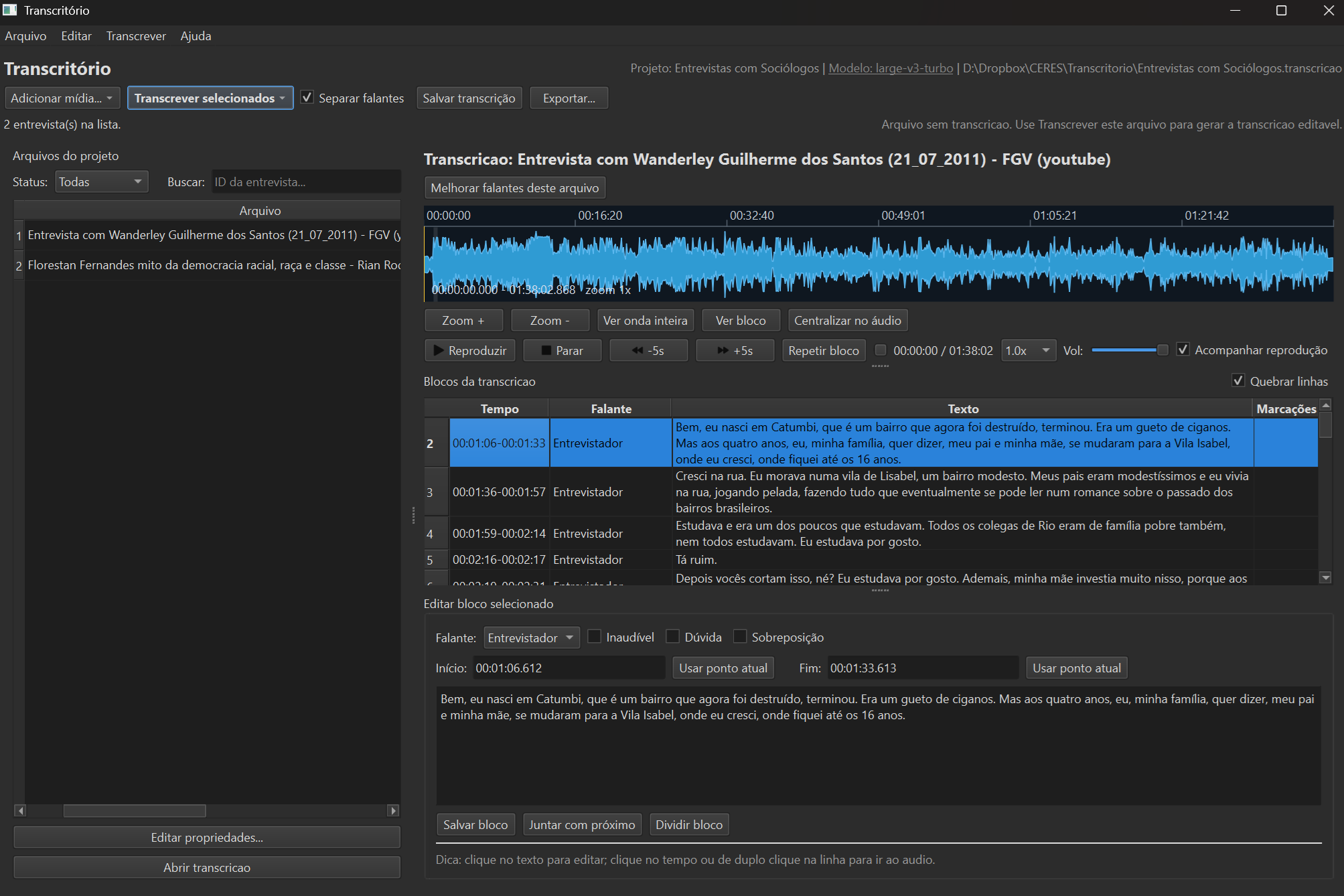
Gerenciador de arquivos do projeto
Todos os áudios do projeto em uma única tela, com status visual de cada etapa: ainda não transcrito, em fila, concluído, revisado. Você acompanha um projeto inteiro — dezenas de entrevistas — sem perder o fio do trabalho.
Revisão lado a lado com o áudio
Ouça e corrija ao mesmo tempo. Cada trecho transcrito fica ancorado no ponto exato do áudio, e um clique leva você até lá. O pesquisador revisa em um terço do tempo que levaria em um editor de texto comum.
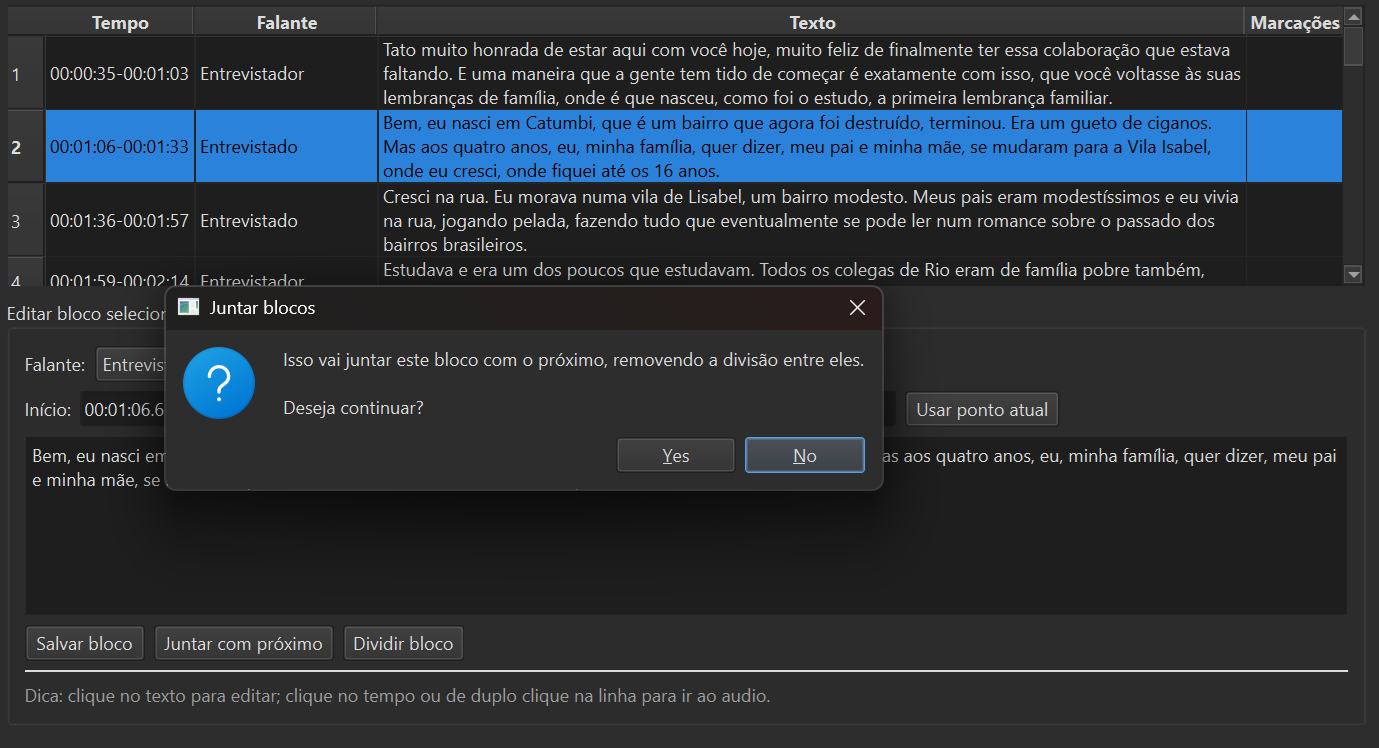
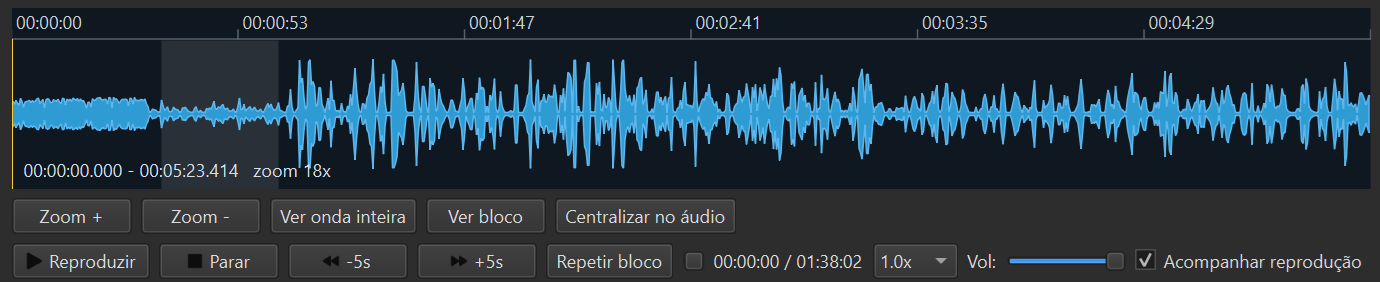
Editor de turnos com forma de onda
A forma de onda mostra visualmente silêncios, sobreposições e trocas de falante. Você ajusta limites de trechos, junta ou divide blocos com um clique — útil em entrevistas com falas rápidas ou interrupções frequentes.
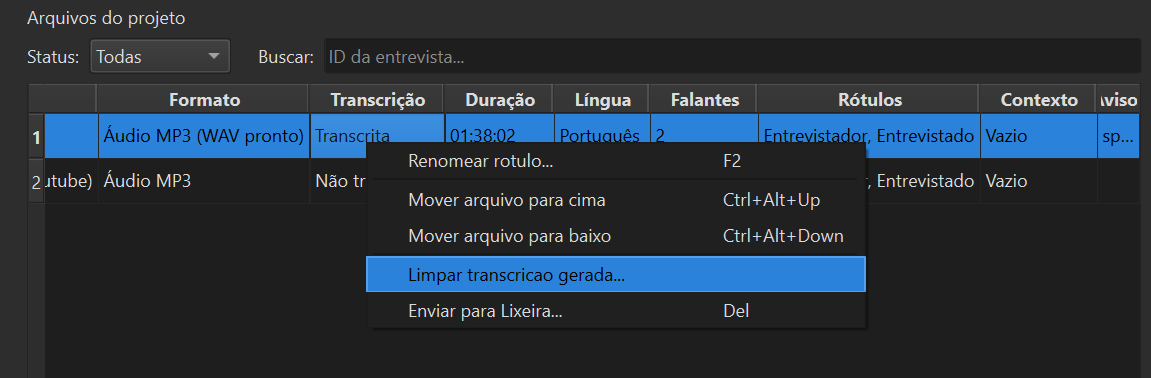
Tabela de turnos pronta para análise
A transcrição é organizada em turnos de fala com metadados de tempo e falante. Exporte em DOCX, MD, SRT, VTT, CSV, TSV ou NVivo — e importe direto no NVivo, Atlas.ti, MAXQDA ou em um script de R/Python.
Como usar, em quatro passos
- 1
Crie um projeto
Escolha um nome para o projeto e uma pasta onde os arquivos serão organizados. O Transcritório cria a estrutura de pastas para você.
- 2
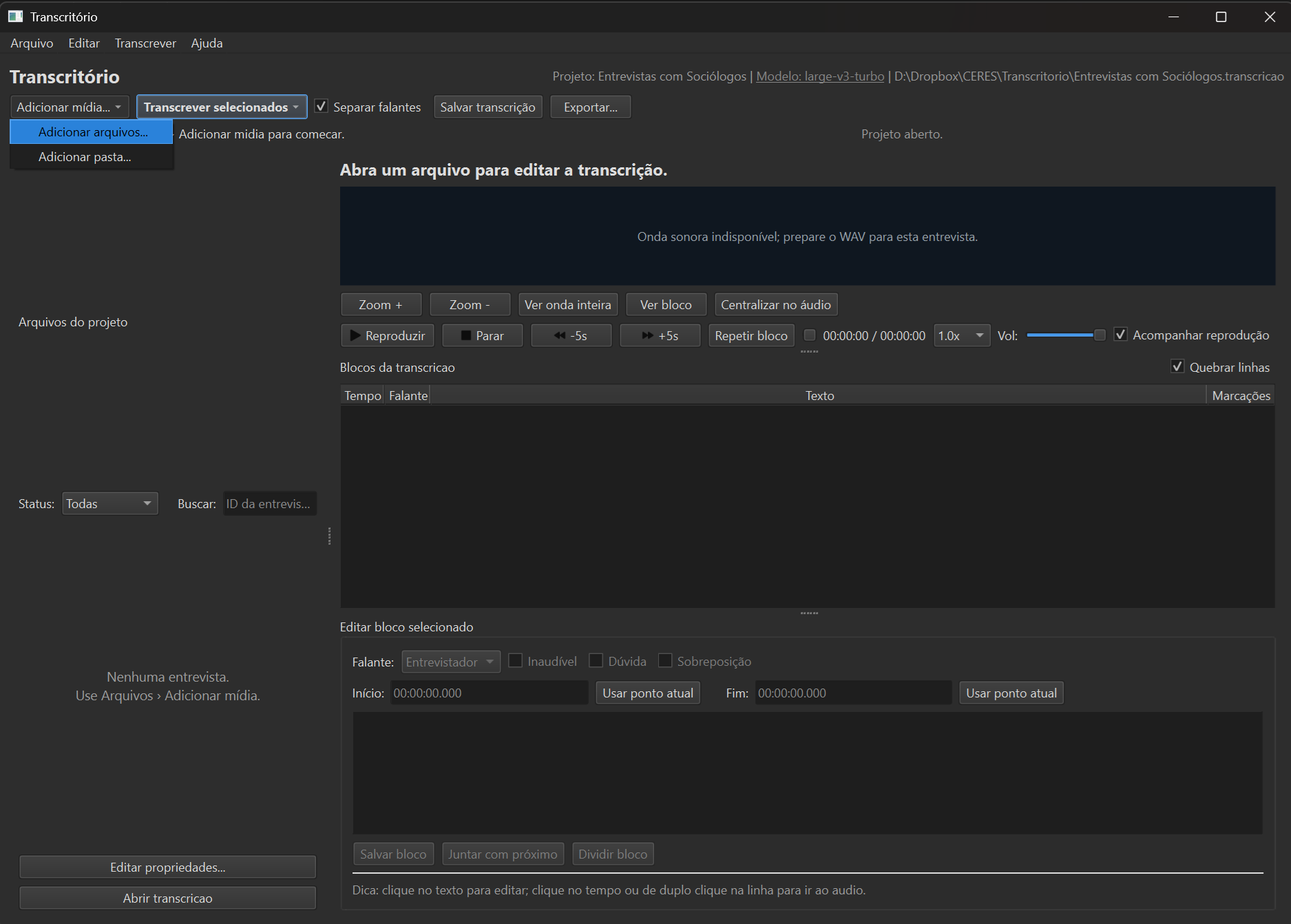
Adicione os áudios ou vídeos
Arraste seus arquivos para a janela. MP3, WAV, M4A, MP4 e outros formatos comuns são aceitos.
- 3
Clique em transcrever
Escolha o idioma (português brasileiro) e o número de falantes. O Transcritório faz o resto — em um notebook comum, processa de metade a um terço da duração do áudio.
- 4
Revise no Estúdio e exporte
Abra a transcrição, ajuste trechos, renomeie os falantes (Entrevistador, Joana, Pedro…) e exporte no formato da sua preferência.
Instalando no seu sistema
🪟 Windows 10/11
- Baixe o arquivo
Transcritorio-0.1.8-Setup.exeda última release. - Execute o instalador. O Windows Defender pode exibir um aviso azul — clique em "Mais informações" e depois em "Executar assim mesmo".
- Abra o Transcritório pelo menu Iniciar.
- Opcional: se você tem placa gráfica NVIDIA, o aplicativo detecta automaticamente e oferece baixar a aceleração (~1 GB), tornando a transcrição até 9x mais rápida.
🍎 macOS (Apple Silicon)
- Baixe o arquivo
Transcritorio.dmgda última release. - Arraste o Transcritório para a pasta Aplicativos.
- Primeira vez: clique com o botão direito no ícone do app e escolha "Abrir". Em seguida, clique em "Abrir" no aviso de segurança. Se o app ainda não abrir (macOS 15 Sequoia bloqueia apps sem Apple Developer ID), clique duas vezes no arquivo
Habilitar Transcritório.commandque vem dentro do mesmo.dmg. Detalhes em docs/MAC_INSTALL.md. - Aceleração Metal automática (M1/M2/M3/M4): o app já vem com a biblioteca de aceleração GPU Apple embutida. Um selo
Motor: MLX (Metal)aparece no cabeçalho do projeto quando a aceleração está ativa. Na primeira transcrição, o modelo otimizado (~1,6 GB) é baixado em segundo plano. - Tudo embutido: ffmpeg e todas as dependências vêm dentro do
.dmg. Nada pra instalar pelo terminal.
🐧 Linux
- Baixe o arquivo
Transcritorio-x86_64.AppImageda última release. - No terminal, dê permissão de execução:
chmod +x Transcritorio-*.AppImage - Instale as bibliotecas do sistema X11 (Ubuntu/Debian):
sudo apt install libfuse2 libxcb-cursor0 libxcb-xinerama0 libxkbcommon-x11-0. ffmpeg já vem embutido no AppImage — não precisa instalar à parte. - Execute com duplo clique ou
./Transcritorio-x86_64.AppImage. Testado em Ubuntu 22.04+ e Fedora 40+.
Requisitos de sistema
- CPU: 4 núcleos
- RAM: 8 GB
- Disco: 5 GB livres
- Funciona — 1h de áudio leva ~40–60 min.
- CPU: 8 núcleos
- RAM: 16 GB
- Disco: 10 GB livres
- 1h de áudio em ~20–30 min.
- CPU: 8+ núcleos
- RAM: 16 GB ou mais
- GPU: NVIDIA com 6 GB+ VRAM (ou Apple Silicon)
- 1h de áudio em 5–10 min.
A inteligência artificial por detrás
(detalhes técnicos)
Whisper (OpenAI, 2022)
Modelo de transcrição automática treinado em 680 mil horas de áudio multilíngue, incluindo grande quantidade de português. O Transcritório usa a versão large-v3 por padrão, que entrega alta acurácia mesmo em áudios com ruído de fundo ou sotaques regionais. Executado localmente via faster-whisper.
pyannote.audio (Bredin et al., 2020)
Biblioteca responsável pela separação automática de falantes — ou seja, por identificar quem falou em cada trecho. Usa redes neurais para agrupar vozes semelhantes ao longo da entrevista. Funciona bem até com 6–8 participantes distintos e também roda offline.
Processamento local
Tanto Whisper quanto pyannote rodam inteiramente no seu computador, via PyTorch. Nenhum áudio, texto ou metadado sai da sua máquina em momento algum. O primeiro uso baixa os pesos dos modelos (~3 GB); depois disso, o aplicativo funciona sem conexão com a internet.
Perguntas frequentes
Preciso de internet para usar?
Apenas no primeiro uso, para baixar os modelos (~3 GB). Depois disso, o Transcritório funciona integralmente offline.
Quão precisa é a transcrição?
Em áudios limpos de português brasileiro, a acurácia fica entre 90% e 96% das palavras corretas. Revisão humana continua sendo recomendada, especialmente para termos técnicos, nomes próprios e trechos com ruído.
E entrevistas com sotaque nordestino, caipira ou sulista?
O modelo Whisper large-v3 foi treinado com ampla variação dialetal em português e lida bem com sotaques regionais brasileiros. A queda de acurácia costuma ser pequena (2–4 pontos percentuais) em comparação a áudios em variante paulistana/carioca padrão.
Minha TI institucional bloqueia instalação de programas. O que faço?
Em Windows e Linux, o Transcritório pode rodar em modo portátil a partir de uma pasta do usuário, sem exigir privilégios de administrador (.AppImage no Linux, versão zipada no Windows sob demanda). Em último caso, peça à TI uma exceção apresentando a licença MIT e o repositório público no GitHub.
Como cito o Transcritório em um artigo ou tese?
Barbosa, R. J. (2026). Transcritório: transcrição local de entrevistas em português brasileiro (v0.1.8) [Software]. IESP-UERJ/CERES.
@software{barbosa2026transcritorio,
author = {Barbosa, Rog{\'e}rio Jer{\^o}nimo},
title = {Transcrit{\'o}rio: transcri{\c{c}}{\~a}o local de entrevistas em portugu{\^e}s brasileiro},
year = {2026},
version = {0.1.8},
publisher = {IESP-UERJ/CERES},
license = {MIT},
url = {https://github.com/antrologos/Transcritorio}
}Preciso de token da Hugging Face para os modelos?
Não no fluxo padrão. O Transcritório já inclui os componentes necessários dos modelos. Um token da Hugging Face só é pedido em cenários avançados (por exemplo, usar modelos de separação de falantes mais recentes manualmente).
Funciona com entrevistas em outros idiomas?
Sim. O Whisper suporta mais de 90 idiomas. O foco do Transcritório é português brasileiro, mas você pode selecionar espanhol, inglês, francês, etc. na interface.
Posso transcrever grupos focais com muitos participantes?
Sim, até cerca de 8 falantes com bons resultados. Acima disso, a separação de falantes começa a misturar vozes parecidas — nesses casos, recomenda-se revisão manual dos rótulos no editor.
O código é realmente aberto? Posso auditar?
Sim. Todo o código-fonte está publicado no GitHub sob licença MIT. Qualquer pessoa pode ler, modificar, redistribuir e verificar o comportamento do aplicativo.
Comece hoje. Seus áudios permanecem com você.
Gratuito, sem cadastro, código aberto.
Ver todas as versões no GitHub