Transcribe interviews without sending your audio to the cloud.
Transcritório is a desktop app for automatic transcription and speaker separation in Brazilian Portuguese. Runs 100% on your machine — no login, no subscription, no data upload.
Windows
Windows 10/11 · 64-bit1.64 GB Click and run the installer macOS
Apple Silicon (M1/M2/M3/M4)608 MB First launch: right-click > Open Linux
x86_64 · AppImage852 MB chmod +x and run Still evaluating? Keep scrolling — 30 seconds to see why researchers are moving away from cloud services.
- 100% local, no cloud
- Automatic speaker separation
- Native Brazilian Portuguese
- Waveform-synced editor
- Multi-format export
- Free and open-source
How your working hours change
Without Transcritório
- 8–10 hours manually transcribing a 1-hour interview.
- Uploading confidential audio to foreign company servers.
- R$ 100–300/month for online transcription services.
- Labeling speakers by hand, line by line.
- Explaining to the ethics board why audio went to the cloud.
With Transcritório
- 15–30 minutes of processing, then just review.
- Audio never leaves your computer.
- Zero cost, forever. Open-source under MIT license.
- Speakers auto-identified and renamable in one click.
- Ready-to-paste text for your research protocol (right below).
Privacy by design, not by promise
- 100% local processing: interview audio never reaches external servers.
- No data collection, no telemetry: no signup or login required.
- Open-source under MIT license: auditable by anyone.
- Compatible with GDPR/LGPD and IRB requirements: full control over informant's audio.
Everything a qualitative researcher needs

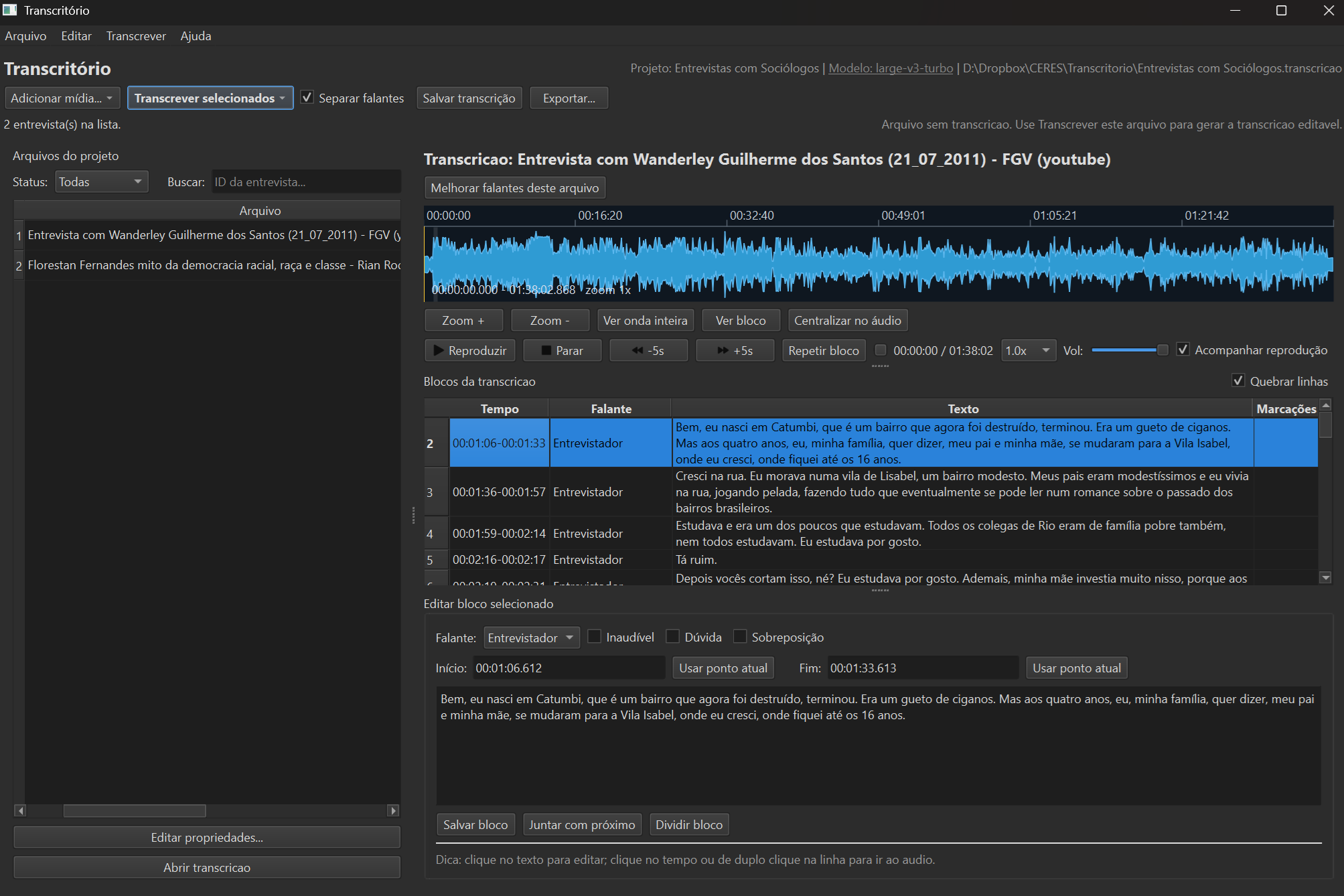
Project file manager
All of your project's audio files in a single screen, with visual status for every stage: not yet transcribed, queued, done, reviewed. You keep track of an entire project — dozens of interviews — without losing the thread of your work.
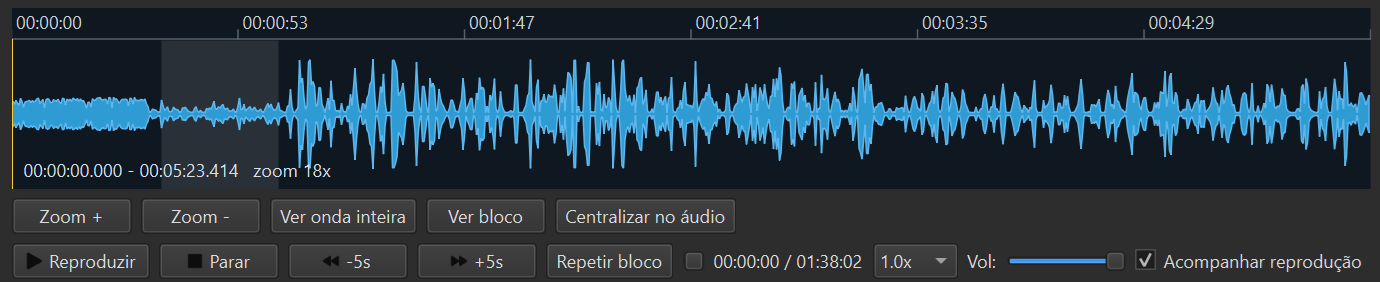
Side-by-side audio review
Listen and correct at the same time. Each transcribed segment is anchored to the exact audio timestamp, and one click takes you there. Researchers review in about a third of the time it would take in a plain text editor.
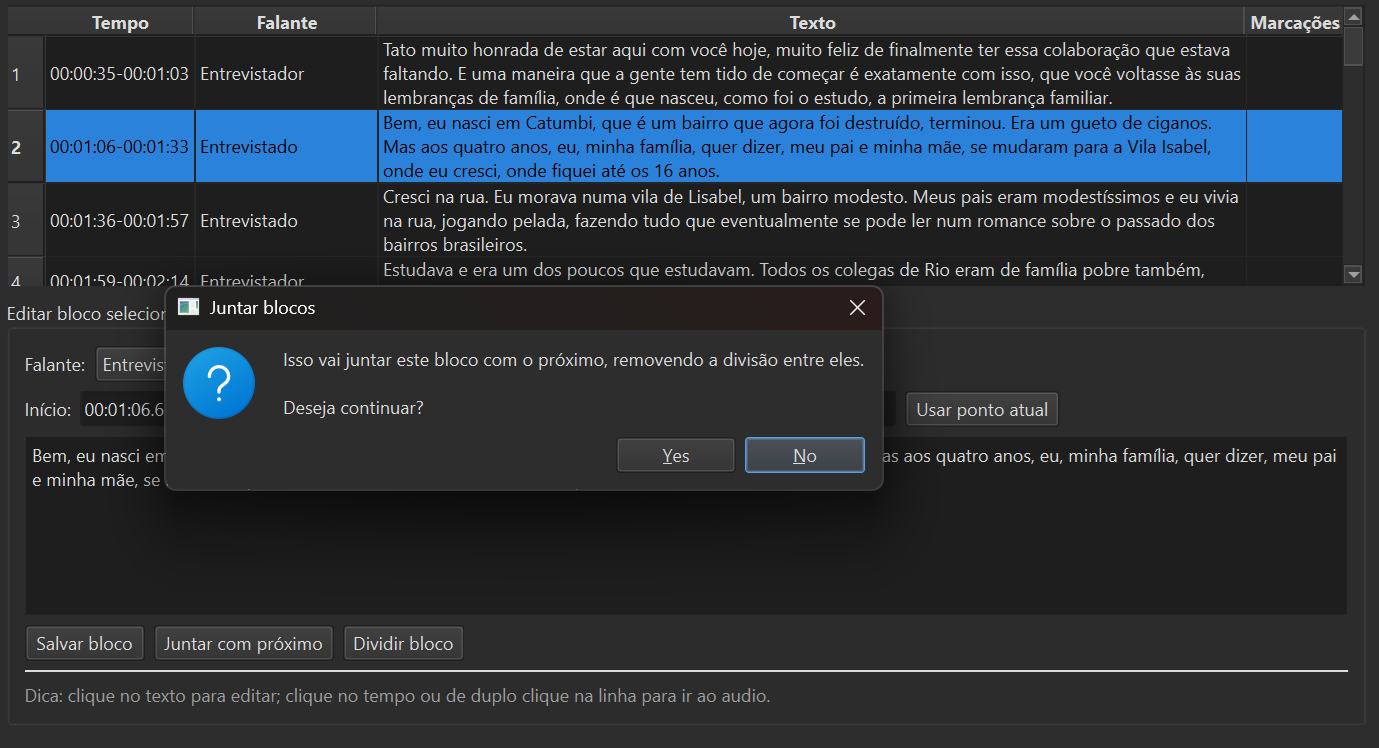
Turn editor with waveform
The waveform visually shows silences, overlaps, and speaker changes. Adjust segment boundaries, merge or split blocks with a click — useful for fast-paced or frequently interrupted interviews.
Analysis-ready turn table
Your transcript is organized into speaking turns with time and speaker metadata. Export to DOCX, MD, SRT, VTT, CSV, TSV or NVivo — and import straight into NVivo, Atlas.ti, MAXQDA, or an R/Python script.
How to use it, in four steps
- 1
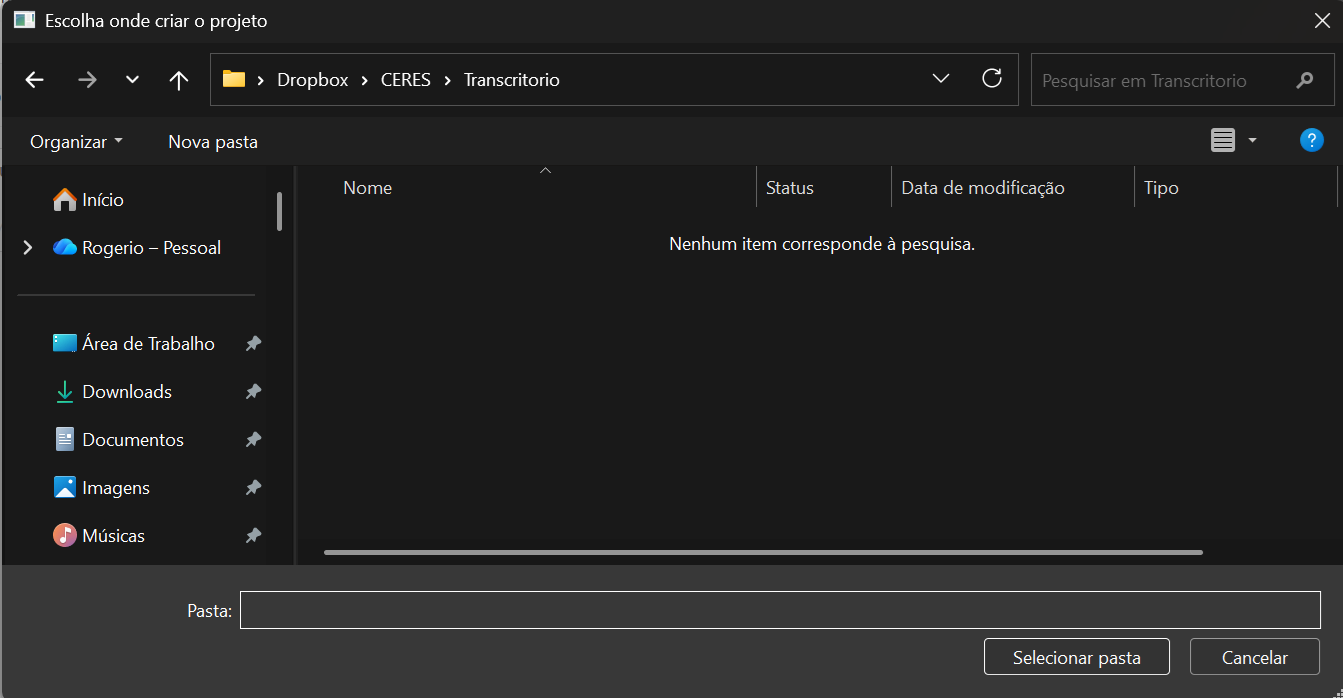
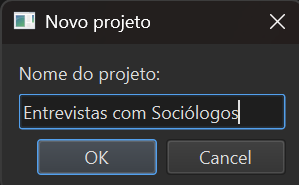
Create a project
Pick a name for your project and a folder where files will be organized. Transcritório creates the folder structure for you.
- 2
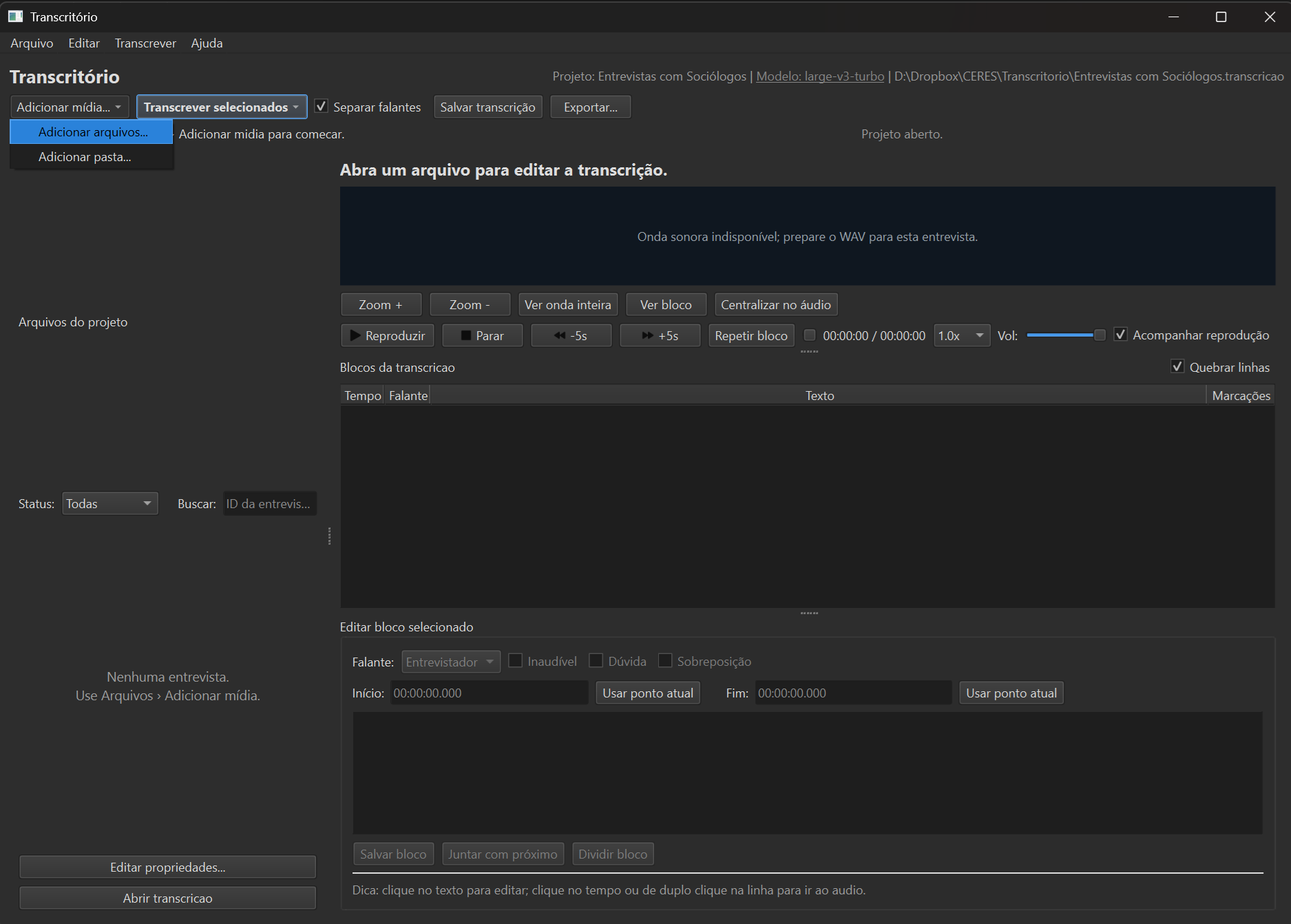
Add audio or video files
Drag your files into the window. MP3, WAV, M4A, MP4 and other common formats are supported.
- 3
Click transcribe
Pick the language (Brazilian Portuguese) and number of speakers. Transcritório does the rest — on a typical laptop, it runs in about a third to half of the audio length.
- 4
Review in the Studio and export
Open the transcript, adjust segments, rename speakers (Interviewer, Joana, Pedro…) and export in your preferred format.
Installing on your system
🪟 Windows 10/11
- Download
Transcritorio-0.1.8-Setup.exefrom the latest release. - Run the installer. Windows Defender may show a blue warning — click "More info", then "Run anyway".
- Open Transcritório from the Start menu.
- Optional: if you have an NVIDIA graphics card, the app auto-detects it and offers to download GPU acceleration (~1 GB), making transcription up to 9× faster.
🍎 macOS (Apple Silicon)
- Download
Transcritorio.dmgfrom the latest release. - Drag Transcritório to the Applications folder.
- First launch: right-click the app icon and choose "Open", then click "Open" in the security dialog. If the app still won't launch (macOS 15 Sequoia blocks apps without a paid Apple Developer ID), open Terminal and drag the
Habilitar Transcritório.commandfile from the mounted DMG into the Terminal window, then press Enter. Full instructions in docs/MAC_INSTALL.md. - Automatic Metal acceleration (M1/M2/M3/M4): the app ships with the Apple GPU acceleration library bundled. A
Motor: MLX (Metal)badge appears in the project header when acceleration is active. On the first transcription, the optimized model (~1.6 GB) is downloaded in the background. - Everything bundled: ffmpeg and all dependencies ship inside the
.dmg. Nothing to install via terminal.
🐧 Linux
- Download
Transcritorio-x86_64.AppImagefrom the latest release. - In the terminal, grant execute permission:
chmod +x Transcritorio-*.AppImage - Install system X11 libs (Ubuntu/Debian):
sudo apt install libfuse2 libxcb-cursor0 libxcb-xinerama0 libxkbcommon-x11-0. ffmpeg ships inside the AppImage — no separate install needed. - Run by double-clicking or
./Transcritorio-x86_64.AppImage. Tested on Ubuntu 22.04+ and Fedora 40+.
System requirements
- CPU: 4 cores
- RAM: 8 GB
- Disk: 5 GB free
- Works — 1h of audio takes ~40–60 min.
- CPU: 8 cores
- RAM: 16 GB
- Disk: 10 GB free
- 1h of audio in ~20–30 min.
- CPU: 8+ cores
- RAM: 16 GB or more
- GPU: NVIDIA 6 GB+ VRAM (or Apple Silicon)
- 1h of audio in 5–10 min.
The AI behind it
(technical details)
Whisper (OpenAI, 2022)
Speech recognition model trained on 680k hours of multilingual audio, including large amounts of Portuguese. Transcritório uses the large-v3 variant by default, delivering high accuracy even on noisy audio or regional accents. Runs locally via faster-whisper.
pyannote.audio (Bredin et al., 2020)
Library handling automatic speaker separation — identifying who spoke when. Uses neural networks to cluster similar voices across the interview. Works well even with 6–8 distinct participants, and also runs offline.
Local processing
Both Whisper and pyannote run entirely on your computer via PyTorch. No audio, text, or metadata ever leaves your machine. First launch downloads model weights (~3 GB); after that, the app runs without an internet connection.
Frequently asked questions
Do I need the internet to use it?
Only on first launch, to download models (~3 GB). After that, Transcritório works fully offline.
How accurate is the transcription?
On clean Brazilian Portuguese audio, accuracy ranges from 90% to 96% of words correct. Human review remains recommended, especially for technical terms, proper names and noisy passages.
What about interviews with strong regional accents?
Whisper large-v3 was trained with wide dialectal variation in Portuguese and handles Brazilian regional accents well. Accuracy drops are usually small (2–4 percentage points) compared to standard Sao Paulo/Rio speech.
My institution's IT blocks software installs. What do I do?
On Windows and Linux, Transcritório can run in portable mode from a user folder, without admin privileges (.AppImage on Linux; zipped build on Windows on request). As a last resort, request an IT exception citing the MIT license and public GitHub repo.
How do I cite Transcritório in a paper or thesis?
Barbosa, R. J. (2026). Transcritório: transcrição local de entrevistas em português brasileiro (v0.1.8) [Software]. IESP-UERJ/CERES.
@software{barbosa2026transcritorio,
author = {Barbosa, Rog{\'e}rio Jer{\^o}nimo},
title = {Transcrit{\'o}rio: transcri{\c{c}}{\~a}o local de entrevistas em portugu{\^e}s brasileiro},
year = {2026},
version = {0.1.8},
publisher = {IESP-UERJ/CERES},
license = {MIT},
url = {https://github.com/antrologos/Transcritorio}
}Do I need a Hugging Face token for the models?
Not in the standard flow. Transcritório ships with the required model components. A Hugging Face token is only required in advanced scenarios (e.g., manually using newer speaker-diarization models).
Does it work with interviews in other languages?
Yes. Whisper supports 90+ languages. Transcritório focuses on Brazilian Portuguese, but Spanish, English, French and others can be selected.
Can I transcribe focus groups with many participants?
Yes, up to about 8 speakers with good results. Beyond that, speaker separation starts mixing similar voices — manual label review in the editor is recommended.
Is the code really open? Can I audit it?
Yes. All source code is published on GitHub under MIT license. Anyone can read, modify, redistribute and verify the app's behavior.